Audio formats are types of files designed to store digital audio data on a computer system. The bit arrangement of audio data (excluding metadata) is called an audio encoding format and can be uncompressed or compressed. Compression is used to reduce file size, which often comes with a loss of audio quality. Audio can also be a raw bitstream in an audio encoding format, but it is usually embedded in an audio data format with some storage layer.
What are they?
An audio file is a collection of information that consists of data about the frequency and amplitude of a sound, stored for later playback.
Audio formats can act as containers for raw data and also use audio codecs. Often these concepts are mixed and confused.
The codec performs encoding and decoding of the raw audio data, while this encoded data is typically stored in a container file. Although most audio file formats only support one type of audio encoding data (created using an audio encoder), a media container format (such as Matroska or AVI) can support multiple types of audio and video data.
MQA and Hi-Res
One of the things that streaming can't handle is delivering high-resolution audio. Recently, the concept of "Hi-Res" has become a little vague. Every audio system manufacturer wants to claim that their equipment provides listeners with the best quality sound by specifying “Hi-Res audio support” in the specifications.
In reality, high-resolution audio is audio with the greatest possible detail and precision. We're a bit dubious about most manufacturers' claims that their products can handle hi-res files. We mainly rely on our sound perception (most often the lack of hi-res is more than obvious). So, let's leave the marketing tricks of the manufacturers and return to our analysis.
In 2014, great progress was made in the field of Hi-Res audio, thanks to which we can listen to recordings in high definition through streaming services. This advanced technology was called MQA (Master Quality Authenticated). Essentially, this audio codec delivers compressed files with completely disproportionate audio quality, using new digitization algorithms to package the entire signal into a FLAC or WAV container and deliver it to you over Wi-Fi.
On the one hand, this is certainly great news for modern connoisseurs of high-quality audio. On the other hand, new technologies did not cause the “streaming revolution” as the creators expected. MQA is available on many platforms, but this format has received a lot of negative reviews and criticism towards the digital processing technologies used. Therefore, most listeners prefer more common formats.
We love experimenting with sound, so we have nothing against MQA. If you're interested, you can listen to MQA audio on Tidal right now thanks to their new Tidal Masters program. TIDAL has partnered with MQA to bring you the best representation of your favorite songs, with an authenticated and undistorted version (standard: 96 kHz / 24 bit).
You'll also need compatible hardware to play MQA audio files - as with DSD, it requires some pretty specialized internal components to make it work. Luckily, streaming audio players are becoming more affordable. Read our selection of the best network audio players.
Varieties by volume and quality
Audio file formats can be divided into the following groups:
1. Uncompressed – such as WAV, AIFF, AU or raw PCM without headers.
2. Lossless compression formats - for example, FLAC, AudioMonkey's (.ape file extension), WavPack (.wv file extension), TTA, ATRAC AdvancedLossless, ALAC (.m4a file extension), MPEG-4 SLS, MPEG- 4 ALS, MPEG-4 DST, WindowsMediaAudioLossless (lossless WMA) and Shorten (SHN).
3. Lossy compressed formats - for example, Opus, MP3, Vorbis, Musepack, AAC, ATRAC and Windows Media Audio Lossy (compressed WMA).
Volume of sound information
The larger the audio file, the better the quality of its playback. The volume of a higher-quality file is always less than the volume of a file with low quality, even if they are of equal duration.
To calculate the amount of information occupied by an audio file with one audio track, use the formula below:
\(V = N * f * k\),
where \(N\) is the total playing time of the audio file, sec,
\(f\) — audio file sampling frequency, Hz,
\(k\) — audio file encoding depth, bits.
Let's consider an example, when the playing time of an audio file is 5 minutes with high quality playback with a sampling frequency of 48000 Hz and a coding depth of 64 bits, then the volume of such a file will be:
\(V = 5 * 60 * 48000 * 64 = 921600000 bits,\)
which is 115,200,000 bytes, or 115,200 KB, or 115.2 MB.
For stereo sound, the volume is calculated using the same formula, with the only difference that you still need to multiply by two, since a file with stereo sound usually takes up twice as much space due to the fact that the sampling process during stereo sound encoding is carried out for each tracks separately.
WAV and AIFF
The AIFF digital audio format is based on the Interchange File Format (IFF), while WAV is based on a similar variation of the Resource Interchange File (RIFF). WAV and AIFF are designed to store a wide range of audio formats, both lossless and lossy. They simply add a small header containing metadata before the audio component to indicate the audio format (for example, LPCM with a specific sample rate, bit depth, sequence numbers, and number of channels). Because WAV and AIFF are widely supported and can store LPCM, they are suitable file formats for storing and archiving the original recording.
Which audio format should I choose? MP3 WMA FLAC WAV CDA
I decided to write an article about audio formats and try to explain it in human language to those who are not in the know.
I will try to avoid abstruse terms and descriptions of characteristics, so as not to once again injure the brains of readers. I’ll admit right away that I won’t sing praises in honor of any particular audio format, just as I’m not going to “put anyone down”. Let everyone decide for themselves. I won’t get into the weeds and will go over the most well-known formats.
I believe that these debates are being conducted by people, to put it mildly, who are not knowledgeable about this topic. Since professionals (that is, people who know what they are doing and why they are doing it) will not engage in such crap. With the current abundance of audio formats, anyone in need will find what they need. Agree, it would look stupid to argue between a tractor driver and a driver about which is better - a tractor or a car. For some purposes - a tractor, for others - a car. It's the same here.
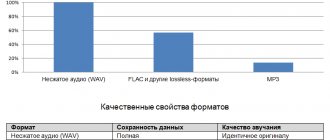
WAV is rightly considered the main audio format. It is used when recording and processing audio, since recording in WAV occurs without compression. Encoded to any other audio format. Well, as a result, it “weighs” quite a lot, so it is used mainly for sound recording.
Next come the various “interpretations”, which can be divided into:
Lossy audio compression I'll start with the well-known and widely used (although not always loved) MP3 format. This audio format is actively used anywhere and everywhere, where it is necessary and where it is not necessary. But this does not mean that he is unworthy of the place he occupies in his niche. Very worthy indeed. Although he has been “sitting” in his niche for about two decades, no one has “kicked” him out of there yet. And there were a lot of people who wanted to say something. And the main favorite of them is WMA (Windows Media Audio), which was conceived by Microsoft as an alternative to MP3. As a result, it is an alternative, despite the efforts of the developers. The next character is OGG. Despite its wider capabilities than MP3, for example, it never received mass recognition. Although it is supported by many operating systems. It is perhaps worth mentioning the AAC audio format, which was supposed to replace MP3 in the relay. It has improved encoding quality and reduced compression losses. But... alas.
The main advantage of these formats is their small size. The downside is loss of quality.
Lossless Audio Compression FLAC is perhaps the most popular lossless audio codec. Music lovers are gradually switching to this format. WavPack is a worthy competitor to it, but is not as popular. It's a similar story with Apple Lossless, which shrinks the size by up to 60%. Skeptics claim that it is almost impossible to distinguish MP3 (320 kbps) from Losless by ear. “If there is no difference, why pay more?” Indeed, it is quite difficult to feel the difference between audio formats using conventional equipment, even for music lovers. But there are also those who immediately feel this difference (I was personally present at the experiment). But when listening on a good device, the difference is huge. The trouble is that not everyone can afford a good device.
Source
New Generation
BWF (Broadcast Wave Format) is a standard audio format created by the European Broadcasting Union as a successor to WAV. It has a ton of improvements, including the ability to store more robust metadata in the file. It is the primary recording format used in many professional workstations in the television and film industries. BWF files include a standardized timestamp that makes it easy to synchronize audio with a specific picture element. Standalone multitrack recorders from AETA, Sound Devices, Zaxcom, HHB Communications Ltd, Fostex, Nagra, Aaton, and TASCAM always use BWF as the preferred format.
What is an audio codec and how does it work?
After the introduction is complete, we must move on to the meat of the matter, for this we must understand that the word “codec” is an abbreviation of the term “encoding-decoding”. It is a processor that from an encoded stream of input data generates another by executing some rules that it follows to decode that data. Said rules may be written in program form in the internal memory of the processor or may be connected to a chip. So there is no difference between an audio codec and a video codec outside of the format they deal with; after all, a data stream is nothing more than an accumulation of bits that need to be processed.
So what's the difference? Well, it is the way in which this data becomes something tangible for the user. Video codecs must be transmitted through the video signal and from there to the screen. On the other hand, in a video codec, the created file will be transferred to the audio output. Of course, there are GPUs that use their compute pipeline to decode and generate audio. What they do is that the HDMI output carries both audio and video signals.
Audio Codecs were thought to save space to be able to transfer data over very slow communication interfaces, but when space and network speed were no longer an issue, their design changed. Ability to encode audio systems in 3D or positional audio to enable multi-speaker systems in multimedia content. This will require some processor power.
Audio formats with and without compression
This type saves data in a smaller volume without losing information. The original data can then be recreated from such a version.
Uncompressed audio formats encode sound and silence with the same number of bits per unit of time. Encoding a minute of absolute silence creates a file the same size as minutes of music. However, in a compressed format, the music will occupy a smaller file than the original recording, and the silence will take up almost no space.
These types of audio file formats include FLAC, WavPack, AudioMonkey, ALAC (Apple Lossless). They provide a compression ratio of about 2:1 (meaning the files take up half the PCM space). Development in lossless compression formats aims to reduce processing time while maintaining good audio quality.
Uncompressed audio formats
There are other audio file formats that do not use data compression. These are the so-called uncompressed audio formats . These file types act as a container for raw audio data without reducing its size or quality in any way.
These are the largest files to work with, but provide the highest level of detail in audio information. Uncompressed audio files are the type most commonly used for recording and mixing music in a DAW .
Even then, uncompressed audio files also come in different levels of quality. They are based on the precision and accuracy with which the analog audio signal was converted to digital. The higher the sample rate and bit depth, the more information is captured during the conversion process.
Bit depth represents the precision of an analog-to-digital converter to measure the amplitude or loudness level of a signal. You can think of it like the number of marks on a ruler—the closer they are, the less often a measurement will fall between two marks.
Sampling rate refers to the number of measurements taken per second. A higher sampling rate means more individual measurements are taken.
Uncompressed audio files are the type most commonly used for recording and mixing music in a DAW.
Here is a list of common quality levels for uncompressed audio:
Lossy compressed audio format
This allows you to further reduce the file size by removing some of the audio information and simplifying the data. This, of course, leads to the fact that the quality of audio formats becomes significantly worse. This uses various techniques (usually through the use of psychoacoustics) to remove parts of the sound that least contribute to the perceived quality and minimize the amount of audible noise added during the compression process. The popular MP3 format is perhaps the most famous example. Additionally, AAC, which can be found in the iTunesMusicStore, is also widely available. Most formats offer a different range of compression rates, usually measured in bit rate. The lower the speed, the smaller the file, and the greater the loss of quality.
AMR standard
As for this format, it is perhaps one of the most low-grade. Its origins are associated with the advent of the first clunky mobile phones, which still could not set ringtones in .mp3 format.
At that time, AMR could still replace natural sound with a certain amount of loss of quality. But this quality cannot be compared with what is offered by more “advanced” formats.
What formats are currently known?
.3GP is a multimedia container format that can contain native AMR, AMR-WB or AMR-WB+ formats, as well as some open variants.
.AAC (Advanced Audio Coding) - based on MPEG-2 and MPEG-4 standards. AAC files are usually ADTS or ADIF containers.
.AAX (Audible.com) is an audiobook format that is a variable bitrate (high quality) M4B file encrypted with DRM. MPB contains AAC or ALAC encoded audio in an MPEG-4 container.
.AIFF is a standard audio file format used by Apple. It can be considered the equivalent of WAV.
.AMR (AMR-NB) is an audio type used primarily for speech recording.
.APE (Ashland Monkey's) is an audio format with lossless compression.
.M4A is MPEG-4 audio used by Apple for unprotected music downloaded from the iTunes Music Store. The audio in an M4A file is typically AAC encoded, although ALAC can also be used without loss of quality.
.M4P is Apple's proprietary digital rights management version of AAC developed by Apple for use with music downloaded from the iTunes Music Store.
.MMF is a type of audio from Samsung used in the ringtone. It was developed by Yamaha and is a multimedia data format.
.MP3 - MPEG Layer III Audio format. This is the most common type of audio file used today. It is also known as MPEG-1 or MPEG-2 and is a unique audio encoding format for digital audio. It uses a form of lossy data compression to encode information using imprecise approximations and discarding partial data. All this is done with the goal of reducing file sizes, typically 10 times those of a CD. At the same time, sound quality is maintained comparable to uncompressed. Compared to CD digital audio quality, MP3 compression quality typically achieves 75-95% size reduction. Thus, this type of file is from 1/4 to 1/20 the size of the original digital audio stream. This is important to ensure file transfer and storage, especially these days when information sharing is so widespread. The basis for this comparison is the digital audio CD format, which requires 1,411,200 bps. A commonly used MP3 encoding setting is CBR 128 kbps, resulting in a file 1/11 (= 9%) the size of the original CD quality file, i.e. 91% compressed.
Lossy MP3 compression works by reducing (or approximating) the fidelity of certain parts of the continuous audio that are considered beyond the auditory resolution of most people. This method is usually called perceptual coding or "psychoacoustics". It uses psychoacoustic models to discard or reduce the precision of components less audible to human hearing, and then records the remaining information in an efficient manner.
.MPC (formerly known as MPEGplus, MPEG+ or MP+) is an open-source audio codec specifically optimized for transparent compression of stereo/audio at bitrates of 160-180 Kbps.
The .OGG, .OGA, MOGG format is a free open container type that supports many other types, the most popular of which is the Vorbis audio format. It offers compression similar to MP3, but is less popular. VJGG (Multi-Track-Single-Logical-StreamOgg-Vorbis) is a multi-channel or multi-track OGG file format.
.WAV is a standard audio file format used primarily on Windows PCs. Typically used to store uncompressed (PCM) CD-quality audio files, which means they can be large in size - around 10 MB per minute. These files may also contain data encoded using various codecs to reduce the size (for example, converting to GSM or MP3 format). WAV files use the RIFF structure. This format preserves the quality of files best.
.WMA is a Microsoft Windows Media Audio format. Designed with digital rights management (DRM) capabilities for copy protection. Previously it was as widely distributed as the OGG or MP3 format.
.WV is a format created for HTML5 video.
Sections of a WAV file
For WAV files, there are quite a few types of sections defined, but most files contain only two of them - a format section ("fmt") and a data section ("data"). These are exactly the sections that are needed to describe the format of audio data samples, and to store the audio data itself.
So, in the simplest case, a WAV file must have a mandatory format section (“fmt”), which contains important parameters describing the signal, such as sampling frequency, and a data section (“data”), which contains the signal data itself (Figure 1 ). All other sections are optional.
Optional sections may include those that define key points, list tool parameters, store application information, etc. All these sections are described in detail below.
All applications using WAV files must be able to read the 2 required sections and selectively ignore the optional sections. A program that copies a WAV file must copy all sections of the WAV file, even those that it does not interpret.
There are no restrictions on the order of sections in a WAV file, except that the format section must precede the data section. Some hard-coded programs expect the format section to be the first section (after the RIFF header), although they should not do this because the specification does not require it.
All sections of the RIFF format and, accordingly, WAVE sections are saved in the following format (table below).
Note that even the above RIFF section follows this format. RIFF and WAVE Section Format
| Bias | Size | Name | Description |
| 0 | 4 | Chunk ID | Section ID |
| 4 | 4 | Chunk Data Size | Section Data Size |
| 8 | Section Data Bytes |
The rest of this article is devoted to describing the different types of Wave sections, their data format, and what that data means.
"fmt" format section
The format section contains information about how the audio data is stored and how it should be played back.
The information includes the type of compression used, number of channels, sampling rate, sample bit depth, and other attributes. Format section structure
| Bias | Size | Name | Description | Meaning |
| 0 | 4 | Chunk ID | Section ID | "fmt" (0x666D7420) |
| 4 | 4 | Chunk Data Size | Section Data Size | 16 + additional data size |
| 8 | 2 | Compression Code | Audio compression type code | 1 — 65 535 |
| 10 | 2 | Number of channels | Number of channels | 1 — 65 535 |
| 12 | 4 | Sample rate | Sampling frequency | 1 - 0xFFFFFFFF |
| 16 | 4 | Average bytes per second | Number of bytes per second | 1 - 0xFFFFFFFF |
| 20 | 2 | Block align | Block size | 1 — 65535 |
| 22 | 2 | Significant bits per sample | Number of significant bits per sample | 2 — 65 535 |
| 24 | 2 | Extra format bytes | Additional format data size | 0 — 65 535 |
| 26 | Additional format data |
Section ID (Chunk ID) and Data Size
The section ID is always “fmt” (0x666D7420).
The data size field is equal to the size of the standard WAV format (16 bytes) plus the size of any additional format bytes needed to support specific audio formats unless it contains uncompressed PCM data. Please note that the section identifier "fmt" ends with a space character (0x20).
Compression Code
The first word in the format data indicates the type of compression used for the audio data.
The table provides a list of examples of compression codes. Audio compression format codes
| Code | Description |
| 0 (0x0000) | Unknown format |
| 1 (0x0001) | PCM/uncompressed data |
| 2 (0x0002) | Microsoft ADPCM |
| 6 (0x0006) | ITU G.711 a-law |
| 7 (0x0007) | ITU G.711 µ-law |
| 17 (0x0011) | IMA ADPCM |
| 20 (0x0016) | ITU G.723 ADPCM (Yamaha) |
| 49 (0x0031) | GSM 6.10 |
| 64 (0x0040) | ITU G.721 ADPCM |
| 80 (0x0050) | MPEG |
| 65,535 (0xFFFF) | Experimental format |
Number of Channels
The number of channels indicates how many individual audio signals are encoded in the audio data section. A value of 1 means mono, 2 means stereo, etc.
Sample Rate
The number of audio samples per second.
Average Bytes Per Second
A value indicating how many bytes of data must be passed per second through the digital-to-analog converter during file playback. This information is useful to determine whether data can flow from the source at the required speed to keep up with playback. This value is simply calculated using the formula:
Bytes per second = Sampling rate × Block size
Block Align
Number of bytes per sample. This value can be calculated using the formula:
Block size = Number of significant bits per sample / 8 × Number of channels
Significant Bits Per Sample
The value indicates the number of bits that form each signal sample. Typically this value is 8, 16, 24 or 32. If the number of bits is not byte aligned (divisible by 8), the number of bytes used per sample is rounded up. Unused bits are set to 0 and ignored.
Extra Format Bytes
Indicates how much further data there is to describe the format. If the compression code is 1 (file with uncompressed PCM data), then there is no additional format information. For other types of compression, additional data may be present and of any size depending on the amount of data needed to decode. If the size of the extra data is not word aligned (not evenly divisible by 2), then an extra byte must be added to the end of the data; but the value in the size field does not change.
Data section
The Wave Data Chunk contains digital audio sample data that can be decoded using the format and compression method specified in the Wave Format Chunk. If the compression code is 1 (uncompressed PCM), then the data is represented as raw sample values. This article describes how uncompressed PCM data is stored and does not go into detail about compressed formats.
WAV files usually contain only one section of data, but there can be multiple such sections if they are contained in a Wave List Chunk "wavl".
Data section structure
| Bias | Length | Name | Description | Meaning |
| 0 | 4 | Chunk ID | Section ID | "data" (0x64617461) |
| 4 | 4 | Chunk Data Size | Section Data Size | depends on the number of samples and compression format |
| 8 | Sample data |
Multichannel digital audio audio samples are stored as interleaved data, which simply means sequential audio samples of multiple channels.
Channel samples are stored sequentially one after another before moving to the next sample time. This is done so that you can play a file without having to read the entire file first. The values in the table below would be stored in the WAV file in the order they are listed in the "Value" column (top to bottom). An example of the order of recording samples for multi-channel audio
| Moment of time | Channel | Meaning |
| 0 | 1 (left) | 0x0053 |
| 2 (right) | 0x0024 | |
| 1 | 1 (left) | 0x0057 |
| 2 (right) | 0x0029 | |
| 2 | 1 (left) | 0x0063 |
| 2 (right) | 0x003C |
When samples are represented by 8 bits, they are defined as unsigned values. All other bit sizes are specified as signed values. For example, a 16-bit sample could have a value in the range -32768 to +32767, where the midpoint (silence, signal voltage is 0) corresponds to the value 0.
As stated previously, all RIFF sections (including WAVE "data" sections) must be word aligned (2 bytes). If the sample data is contained in an odd number of bytes, an alignment zero byte must be added to the end of the data. The size of the "data" section header should not take into account this alignment byte.
Section "fact"
The fact section contains information about the contents of the WAV file, depending on the compression format.
It is required for all compressed WAVE formats and if the audio data is contained within the "wavl" list section, but is not required for the uncompressed PCM WAVE format (compression format code is 1), which contains audio data in the "data" section. Structure of the “fact” section
| Bias | Size | Name | Description | Meaning |
| 0 | 4 | Chunk ID | Section ID | "fact" (0x66616374) |
| 4 | 4 | Chunk Data Size | Section Data Size | depends on the format |
| 8 | Format Dependant Data | Format-dependent data |
Format Dependant Data There is
currently only one field defined for format dependent data. This is a single 4-byte value that specifies the number of samples in the data section of the audio signal. This value can be used in conjunction with the Samples Per Second value specified in the format section to calculate the duration of the signal in seconds.
As new WAVE formats become available, the fact section will be expanded by adding fields after the number of samples field. Applications can use the size of the fact section to determine which fields are represented in the section.
Wave list section – “wavl”
The Wave list chunk is used to specify multiple interleavings of "slnt" and "data" sections. These sections can help reduce file size by specifying audible sample segments when the audio data stream contains multiple intervals of silence.
This type of section is considered by many programmers to be an abuse of the WAV file format and its use is not recommended. Also many applications will not recognize this section type and will simply ignore it. This compression format unnecessarily adds complexity to the WAV file structure and can be advantageously implemented in other ways, including several existing compression formats.
| Bias | Size | Name | Description | Meaning |
| 0 | 4 | Chunk ID | Section ID | "wavl" (0x736C6E74) |
| 4 | 4 | Chunk Data Size | Section Data Size | depends on the size of the “data” and “slnt” sections |
| 8 | List of alternating sections “slnt” and “data” |
Silence section – “slnt”
The silent chunk is used to indicate a segment of audio pause that has a certain duration in the signal samples. The silence section is always contained only within the Wave list section (wave list chunk). When this section declares silence, there is no need to set the volume to zero or the base sample. It actually holds the last waveform sample read from the previous Wave Data Chunk in the Wave list chunk. If there were no previous data sections, then a sample base value of 127 for 8-bit data, 0 for 16-bit data, and all data with more bits per sample must be used. These requirements may seem trivial, but if they are not met, unwanted clicks and pops may appear in the audio signal.
| Bias | Size | Name | Description | Meaning |
| 0 | 4 | Chunk ID | Section ID | "slnt" (0x736C6E74) |
| 4 | 4 | Chunk Data Size | Section Data Size | 4 |
| 8 | 4 | Number of Silent Samples | Number of silence samples | 0 - 0xFFFFFFFF |
Number of Silent Samples This value specifies the number of silent samples that should appear in the audio signal at this wave list chunk.
Section of key points – “cue“
The "cue" section defines one or more sample offsets, which are often used to mark key sections of audio data. For example, the beginning and end of a verse in a song may have markers that make them easier to find. The keypoint section is optional, and if added, one keypoint section must specify all the keypoints of the "WAVE" section. Within the “WAVE” section, more than one “cue” section is not allowed.
| Bias | Size | Name | Description | Meaning |
| 0 | 4 | Chunk ID | Section ID | "cue" (0x63756520) |
| 4 | 4 | Chunk Data Size | Section Data Size | Depends on the number of key points |
| 8 | 4 | Num Cue Points | Number of key points in the list | |
| 12 | List of Cue Points | List of key points |
Chunk ID and Chunk Data Size The chunk ID for a cue point section is always “cue” (0x666D7420).
Note that the ID string ends with a space character (0x20). The section data size is equal to the size of the Num Cue Points field (4 bytes) plus the number of subsequent cue points multiplied by the data size of each point (24 bytes). The following formula can be used to calculate the data size of a cue point section: ChunkDataSize = 4 + (NumCuePoints × 24) Num Cue Points This value indicates the number of subsequent cue points in that section. List of Cue Points A list of cue points is simply a collection of descriptions of sequential points and has the following format.
| Bias | Size | Name | Meaning |
| 0 | 4 | ID | Unique identificator |
| 4 | 4 | Position | Playback order position |
| 8 | 4 | Data Chunk ID | RIFF ID of the corresponding data section |
| 12 | 4 | Chunk Start | Byte offset of data section |
| 16 | 4 | Block Start | Byte offset to first channel sample |
| 20 | 4 | Sample Offset | Byte offset to first channel sample byte |
ID Each cue point has a unique identifier, which is used to associate cue points with information in other sections. For example, a Label chunk contains text that describes a point in a WAV file with a link to its associated key point. Position Determines the offset of the sample associated with the keypoint, in terms of the position of the sample in the final stream of samples generated by the playlist. In other words, if a play list chunk is specified, the value of the position is equal to the sample number at which that key point will occur when the entire play list is played back in the specified order. If there is no play list chunk, then the position value must be 0. Data Chunk ID Specifies the 4-byte ID used by the chunk containing the sample that corresponds to this cue point. In a WAV file without a play list chunk, this value is always "data". In a WAV file that has a play list chunk with data and silence sections, this value can be either "data" or "slnt". Chunk Start Specifies the byte offset in the Wave List Chunk of the section containing the sample corresponding to this point. This is the same section described by the Data Chunk ID value. If the WAV file does not have a Wave List Chunk, this value is 0, otherwise this value is equal to the offset in the "wavl" section. The first section in the Wave List Chunk is indicated by the value 0. Block Start Specifies the byte offset in the "data" section or "slnt" section for the start of the block containing the sample. The start of the block specifies the first byte of uncompressed PCM audio data or the last byte in compressed audio data where decoding can begin to find the corresponding sample value. Sample Offset Specifies the offset in the block (specified by Block Start) for the sample corresponding to the key point. In uncompressed PCM audio data, this is simply a byte offset in the "data" section. In compressed audio data, this value is equal to the number of samples (which may not be in bytes) from Block Start to the sample corresponding to the key point.
Playlist section – “plst”
The playlist section specifies the order in which a sequence of cue points will be played. These points are specified in the “cue” section, somewhere else in the file. A playlist consists of an array of segments, each of which contains information about which sample the segment should start playing from, the duration of the segment (in samples), and how many times the segment should be repeated before moving on to the next segment in the list.
| Bias | Size | Name | Description | Meaning |
| 0 | 4 | Chunk ID | Section ID | "plst" (0x736C6E74) |
| 4 | 4 | Chunk Data Size | Section Data Size | number of segments × 12 |
| 8 | 4 | Number of Segments | Number of segments | 1 - 0xFFFFFFFF |
| 12 | List of Segments | List of segments |
Number of Segments Sets the number of subsequent segments in the playlist section.
List of Segments A list of segments is simply a collection of sequential segment descriptions that follow the format shown in the table below. The segments do not have to be in any particular order because the position of the cue point associated with the segment is used to determine the playback order.
| Bias | Size | Name | Description | Meaning |
| 0x00 | 4 | Cue Point ID | Keypoint ID | 0 - 0xFFFFFFFF |
| 0x04 | 4 | Length (in samples) | Length (in samples) | 1 - 0xFFFFFFFF |
| 0x08 | 4 | Number of Repeats | Number of repetitions | 1 - 0xFFFFFFFF |
Cue Point ID Specifies the initial sample for this segment by specifying the cue point value specified in the cue point list. The ID connecting this segment to a key point must be unique in relation to the key point IDs of all other segments. Length Specifies the number of samples to play back from the initial sample specified in the Cue Point ID. Number of Repeats Determines how many times a segment should be played back before moving on to the next segment.
Linked data list section – “list”
The Associated Data List Chunk is used to define text labels and names that are associated with key points, providing each item with a text label or name.
| Bias | Size | Name | Description | Meaning |
| 0 | 4 | Chunk ID | Section ID | "list" (0x6C696E74) |
| 4 | 4 | Chunk Data Size | Section Data Size | depends on the contained text |
| 8 | 4 | Type ID | Type ID | "adtl" (0x6164746C) |
| 12 | List of text labels and names |
Type ID The type identifier is used to indicate the type of linked list of data and is always "adtl". List of Text Labels and Names Simply a list of sorted sections that define text in various ways. WAVE files use three main types of sections—Label Chunk, Note Chunk, and Labeled Text Chunk.
Label section – “labl”
A Label Chunk is always contained within an Associated Data List Chunk. It is used to associate a text cue with a cue point. This information is often displayed on markers or checkboxes in audio editors.
| Bias | Size | Name | Description | Meaning |
| 0 | 4 | Chunk ID | Section ID | "labl" (0x6C61626C) |
| 4 | 4 | Chunk Data Size | Section Data Size | depends on the contained text |
| 8 | 4 | Cue Point ID | Keypoint ID | 0 - 0xFFFFFFFF |
| 12 | text |
Cue Point ID Specifies the sample location point corresponding to this text cue by providing the cue point ID specified in the Cue Point List. The ID that associates this cue with a cue point must be unique with respect to the Cue Point IDs of all other cues. Text A string of characters terminated by zero. If the number of characters in a line is odd, one padding byte must be added to the line. The added padding is not counted in the label section size field.
Note or comment section – “note”
A Note Chunk is always contained within an Associated Data List Chunk. It is used to associate a text comment with a key point. This information is stored in the same way as marks in the mark section.
| Bias | Size | Name | Description | Meaning |
| 0 | 4 | Chunk ID | Section ID | "note" (0x6E6F7465) |
| 4 | 4 | Chunk Data Size | Section Data Size | depends on the contained text |
| 8 | 4 | Cue Point ID | Keypoint ID | 0 - 0xFFFFFFFF |
| 12 | text |
Cue Point ID Indicates the sample location point corresponding to this text note by providing the ID of the cue point specified in the Cue Point List. The ID that associates this note with a cue point must be unique relative to the key point IDs of all other notes. Text A string of characters terminated by zero. If the number of characters in a line is odd, one padding byte must be added to the line. The added padding is not taken into account in the note (comment) section size field.
Tagged text section – “ltxt”
A Labeled Text Chunk is always contained within an Associated Data List Chunk. It is used to associate a text label with an area or section of audio data. This information is often displayed in labeled audio areas in audio editors.
| Bias | Size | Name | Description | Meaning |
| 0 | 4 | Chunk ID | Section ID | "ltxt" (0x6C747874) |
| 4 | 4 | Chunk Data Size | Section Data Size | depends on the contained text |
| 8 | 4 | Cue Point ID | Keypoint ID | 0 - 0xFFFFFFFF |
| 12 | 4 | Sample Length | Number of samples | 0 - 0xFFFFFFFF |
| 16 | 4 | Purpose ID | Destination ID | 0 - 0xFFFFFFFF |
| 20 | 2 | Country | A country | 0 - 0xFFFF |
| 22 | 2 | Language | Language | 0 - 0xFFFF |
| 24 | 2 | Dialect | Dialect | 0 - 0xFFFF |
| 26 | 2 | Code Page | Code page | 0 - 0xFFFF |
| 28 | text |
Cue Point ID Specifies the initial sample that corresponds to this text cue by providing the cue point ID specified in the Cue Point List. The keypoint ID associated with this label must be unique with respect to the keypoint IDs of other labels. Sample Length Specifies how many samples are included in the area or interval of the section, starting from the key point. Purpose ID Indicates what the text is used for. For example, the value "scrp" means script text, "capt" means "close caption" (subtitles). There are more Purpose ID values, but they are intended for use with other RIFF file types and are not typically used in WAVE files. Country, Language, Dialect, Code Page These fields (Country, Language, Dialect, Code Page) are used to specify information about the location and language used in the text. They are usually needed for requests to obtain information from the operating system. Text A string of characters terminated by zero. If the number of characters in a line is odd, one padding byte must be added to the line. The added padding is not counted in the section size field.
Sampler section – “smpl”
The Sampler Chunk specifies the instrument's basic parameters, such as the MIDI sampler that should be used to play back the audio data. Most importantly, it includes information about audio looping during playback. Of course, you might think that this is a duplication of information that can be found in the cue points and playlist sections of the WAVE format, but fortunately the sampler section does this in a more flexible, consistent, and better documented way.
| Bias | Size | Name | Meaning |
| 0 | 4 | Chunk ID | "smpl" (0x736D706C) |
| 4 | 4 | Chunk Data Size | 36 + (Num Sample Loops * 24) + Sampler Data |
| 8 | 4 | Manufacturer | 0 - 0xFFFFFFFF |
| 12 | 4 | Product | 0 - 0xFFFFFFFF |
| 16 | 4 | Sample Period | 0 - 0xFFFFFFFF |
| 20 | 4 | MIDI Unity Note | 0 — 127 |
| 24 | 4 | MIDI Pitch Fraction | 0 - 0xFFFFFFFF |
| 28 | 4 | SMPTE Format | 0, 24, 25, 29, 30 |
| 32 | 4 | SMPTE Offset | 0 - 0xFFFFFFFF |
| 36 | 4 | Num Sample Loops | 0 - 0xFFFFFFFF |
| 40 | 4 | Sample Data | 0 - 0xFFFFFFFF |
| 44 | List of Sample Loops | ||
Manufacturer
The Manufacturer field specifies the MIDI Manufacturer's Association (MMA) code for the sampler intended to receive the audio of this file. Each MIDI product manufacturer has a unique ID that identifies the company. If a specific manufacturer is not specified, the value should be set to 0.
The value contains some additional information that can be used to translate into a value used in the transfer to the MIDI System Exclusive format sampler. The high byte indicates the number of low bytes (1 or 3) that are significant to the manufacturer's code. For example, the value for Digidesign would be 0x01000013 (0x13), and the value for Microsoft would be 0x03000041 (0x00, 0x00, 0x41).
Product The Product field specifies the MIDI model ID as specified by the manufacturer. Contact the sampler manufacturer for product IDs. Unless a specific manufacturer's product is specified, the value should be set to 0. Sample Period The sample period specifies the length of time to play one sample in nanoseconds (usually equal to 1 / samples per second, where samples per second is the value specified in the format section). MIDI Unity Note A value that has the same meaning as the MIDI Unshifted Note of an instrument chunk. The MIDI Unshifted Note field specifies the musical note at which the sample will be played back at its original sample rate (the sample rate is specified in the format section). MIDI Pitch Fraction Indicates the fractions of a semitone up from the value specified in the MIDI Unity Note field. A value of 0x80000000 means 1/2 semitone (50 cents), and a value of 0x00000000 means fine adjustment between semitones. SMPTE Format
Specifies the Society of Motion Pictures and Television E time format used in the following SMPTE Offset field. If set to 0, SMPTE Offset must also be 0.
| Meaning | SMPTE Format |
| 0 | no SMPTE offset |
| 24 | 24 fps |
| 25 | 25 fps |
| 29 | 30 fps with frame dropout (30th frame drops out) |
| 30 | 30fps |
SMPTE Offset A value indicating the time offset used to synchronize/calibrate the first audio sample.
The format is 0xhhmmssff, where hh is a signed number indicating the number of hours (-23 .. 23), mm is an unsigned number of minutes (0 .. 59), ss is an unsigned number of seconds (0 .. 59), and ff – unsigned value of the number of frames (0 .. -1). Sample Loops The sample loops field specifies the number of sample loop definitions in the subsequent list (see List of Sample Loops). This value can be set to 0, which means no subsequent loops will occur. Sampler Data Indicates the number of bytes that will follow this section (including the entire List of Sample Loops). This value is greater than zero when the application needs to store additional information. This value affects the value of the section size field. List of Sample Loops A loop list is a simple collection of sequential loop descriptions that follow the format described below. The loops do not have any particular order, since each sample loop is associated with a cue point, the position of which is used to determine the order of playback. The sampler section is optional.
| Bias | Size | Name | Meaning |
| 0 | 4 | Cue Point ID | 0 - 0xFFFFFFFF |
| 4 | 4 | Type | 0 - 0xFFFFFFFF |
| 8 | 4 | Start | 0 - 0xFFFFFFFF |
| 12 | 4 | End | 0 - 0xFFFFFFFF |
| 16 | 4 | Fraction | 0 - 0xFFFFFFFF |
| 20 | 4 | Play Count | 0 - 0xFFFFFFFF |
Cue Point ID The Cue Point ID specifies a unique ID that corresponds to one of the specified cue points in the list.
Additionally, this ID matches any of the labels specified in the associated data section, which allows text labels to be assigned to different sample cycles. Type The type field specifies how audio samples are looped.
| Meaning | Loop Type |
| 0 | Forward cycle (regular) |
| 1 | Alternate loop (forward↔backward, also known as Ping Pong) |
| 2 | Loop back (reverse) |
| 3 — 31 | Reserved for future standard types |
| 32 - 0xFFFFFFFF | Sampler specific types (set by manufacturer) |
Start The start value specifies the byte offset to the audio data of the first sample played in the loop. End The end value specifies the byte offset to the audio data of the last sample played in the loop. Fraction The fractional value specifies the fractional portion of the sample that belongs to the cycle. This allows you to fine-tune the cycle time with an accuracy greater than that allowed by a single sample. The value can be in the range 0x00000000 .. 0xFFFFFFFF. A value of 0 means no fractional part, a value of 0x80000000 means 1/2 of the sampling duration. The value 0xFFFFFFFF corresponds to the minimum fractional fraction of the sample that can be specified. Play Count The play counter value determines the number of times the loop will be played. 0 means an infinite loop that will not be interrupted until there is a forced external intervention (for example, the musician releases the key). All other values indicate the absolute number of times the loop has been played.
Instrument section – “inst”
An instrument chunk is used to describe how a sound should be played as an instrument sound. This information is useful for exchanging musical information between sample-based music editors, trackers, or software sound tables. This section is optional and cannot appear more than once in a WAVE file.
| Bias | Size | Name | Meaning |
| 0 | 4 | Chunk ID | "ltxt" (0x6C747874) |
| 4 | 4 | Chunk Data Size | 7 |
| 8 | 1 | Unshifted Note | 0 — 127 |
| 9 | 1 | Fine Tune (dB) | -50 — +50 |
| 10 | 1 | Gain | -64 — +64 |
| 11 | 1 | Low Note | 0 — 127 |
| 12 | 1 | High Note | 0 — 127 |
| 13 | 1 | Low Velocity | 1 — 127 |
| 14 | 1 | High Velocity | 1 — 127 |
Unshifted Note The unshifted note field has the same purpose as the MIDI Unity Note section of the sampler - it specifies the musical note at which the sample will be played at its original rate (the sample rate specified in the format section). Fine Tune The fine tune value specifies how much the sample pitch should be changed when the sound is played back in cents (1/100 of a semitone). A negative value means the pitch should be lowered, and a positive value means the pitch should be raised. Gain The gain value specifies the number of decibels to adjust the output signal during playback. A value of 0 dB means no change, 6 dB means the amplitude of each sample is doubled, -6 dB means the amplitude of each sample is halved. Each additional +/- 6 dB doubles or halves the amplitude, respectively. Low Note and High Note Note fields indicate the range of MIDI notes at which the sound should be played when a MIDI note receive event occurs (from software or a MIDI controller command. The controller could be a MIDI keyboard, for example). This range does not need to include the Unshifted Note value. Low Velocity and High Velocity Velocity fields indicate the range of MIDI velocities at which the sound should be played. 1 refers to the slowest playback, 127 to the fastest.
Designed for a specific purpose
.ACT is a compressed ADPCM audio format up to 8 kbps. It records from most Chinese MP3 and MP4 players and voice recorders.
.AU is a standard audio file format used by Sun, Unix, and Java. Audio in AU files can be PCM or compressed using μ-law, a-law or G729 codecs.
.AWB (AMR-WB) - Audio used primarily for speech, similar to ITU-T specification G.722.2.
.DCT – This is used by the NCH software. This is a variable codec format designed for dictation. It has dictation header information and can be encrypted (as required by medical privacy laws). It can also be said that it is a proprietary NCH software format.
.DSS - Olympus DSS files are proprietary Olympus formats. This is a pretty old and bad codec. GSM or MP3 are generally preferred if the recorder allows them to be used. This makes it possible to store additional data in the file header.
.DVF is Sony's proprietary format for compressed voice files, commonly used by the company's voice recorders.
.GSM - designed for use in telephony in Europe. This is the best audio format for high-quality voice sound on the phone. A good compromise between file size and quality. It's also worth noting that WAV files can sometimes be encoded using the GSM codec.
.MSV is Sony's proprietary format for Memory Stick compressed voice files.
Common audio file formats
Audio files come in various formats. Let's look at the most common of them:
- MP3 is a digital format that allows you to record and store audio information, and also provides fairly high quality playback.
- MIDI - this format was initially used only in the process of controlling musical instruments. Today it is used for electronic musical instruments and computer modular systems.
- WAV is a format of arbitrary sound, represented as a vibration or audio wave. It is used in all standard sounds in the Windows system.
Internet formats
.FLAC is a file format for Free Lossless Audio Codec, a lossless audio compression codec.
.IKLAX is a multi-track digital audio format that allows you to perform various operations on music data, such as shuffling and tom building.
.IVS is a proprietary version with Digital Rights Management developed by 3D Solar UK Ltd for use in music downloaded from the Tronme music store, as well as for interactive music and video players.
.OPUS (Internet Engineering Task Force) is a lossy audio compression format developed by the Internet Engineering Task Force (IETF) and created specifically for real-time interactive applications over the Internet. Provided as an open type standardized by RFC 6716, its reference implementation is provided under the 3-section BSD license.
.RA, .RM - Real Audio format designed for streaming audio over the Internet. However, .RA allows you to store files offline on your computer with all the audio data contained in the file itself. Programs for audio formats of this type are now considered obsolete.
All modern audio formats in order of improved sound quality
In the digital age, the question “which listening format to choose” seems rather strange. After all, the market is full of streaming services, streaming - subscribe, find any album, press a button, everything plays. This is not what it used to be - go to the store, buy physical media... After all, if you want luxurious quality, there are online markets for Hi-Res content. However, what do we actually get by listening to music in such formats? And what do we lose? The editors of Hi-Fi.ru are publishing an absolute quality rating of all modern ways of listening to music - we hope that this material will dot the i's in this difficult issue and help to understand why vinyl is still the most vibrant of all living things, and some audiophiles prefer magnetic tape .
MP3, AAC and other compressed formats
Quality score – 5%
The good old MP3 was developed in an era when we only dreamed of high Internet speeds, and terabyte storage of information seemed a thing of the distant future. Now the format is suitable only for familiarization with the melody - distorted timbres, shifted tonal balance, poor detail are unlikely to be of interest to lovers of high fidelity playback.
| + | Huge track library | – | Quality has little relation to original design |
Verdict – “shazamed” – “familiarized”
FLAC, PCM 16/44 – uncompressed formats
Quality score – 15%
| + | Mass format for streaming | – | Significant losses in every sense |
Verdict – there will be no pleasure, but the format gives a general idea of the track
CD (compact disc)
Quality score – 20%
Why did we mention CD in the list when we have already described this approach “digitally” above? There are two answers. Firstly, many audiophiles have collections of thousands of “compacts”, so the plastic circles will last for a long time. Secondly, oddly enough, on a good transport or player https://www.hi-fi.ru/magazine/audio/top50-cd/ CD “with one left” puts its digital image on the shoulder blades - offering better lower mids and permission. And if we add various options for “improved” disks (for example, gold), we will get a good field for experimentation.
| + | Sounds better than 16/44 | – | The losses are still great - the bass is cut off, the dynamics suffer |
Verdict – collectors' choice
Hi-Res PCM, FLAC 24/96 – 24/192
Quality score – 25%
High resolution has finally come to our homes - today the Internet is full of stores with similar content, and most streaming services have broadcasting options with a resolution of 24 bits. Compared to CD, the spatial picture and detail are much better here.
| + | Clearly better than CD if mastered well | – | Still limited bass talent |
Verdict - the format is gradually becoming widespread and replacing all of the above schemes, however, it is not ideal
DVD-Audio
Quality score – 25%
DVD-Audio quickly took off and left the scene just as quickly. Today, this Hi-Res version on disc has become a collector's item - or bits in the files of the corresponding digital content being sold.
| + | All the benefits of a high signal bit rate | – | The sound quality is no better than “regular” Hi-Res, there are no players for playback |
Verdict - only for lovers of the rarest
Quality score – 25%
The brainchild of Bob Stewart of Meridian, who proposed a combination of lossy compression and a fingerprint shape to restore the original sequence. The scheme took root in streaming and offered both good quality and better optimization for broadcasts.
| + | Sounds interesting | – | All the same as described above for Hi-Res |
Verdict - no miracle happened, but as an option to listen to music while jogging with headphones, why not?
Compact cassette
Quality score – 40%
The compact cassette, although it has a number of significant disadvantages (low signal-to-noise ratio, for example), provides a very flexible and natural sound. There are no sparkling high frequencies here, but the tape, even in such a truncated circuit, has its own magic. And given that many releases are now released on cassettes , there is reason to pay attention to the format. New cassette decks are also coming out - but you can also pay attention to vintage ones .
| + | Live, mercurial sound | – | Detail is missing stars from the sky |
Verdict – you can plunge back into a bygone era
DSD128
Quality score – 40%
Sony's one-bit studio format today boasts a fairly large library and offers significantly better channel separation and dynamic range than the "younger" versions of Hi-Res PCM.
| + | Sophisticated sound that can impress | – | The density of sound images is not always at its best |
The verdict is a clear step forward
Quality score – 45%
As usual, disc media performs slightly better than its digital counterpart - and in the case of SACD, the physical format will offer you a slightly better spatial picture. But it will also cost more.
| + | Nice library, nice sound | – | The sound is still not dense enough |
Verdict - If you're a CD collector, it's worth a look.
Hi-Res PCM 32/384 – 32/768
Quality score – 50%
The most advanced Hi-Res options are 32-bit. There are very few such recordings, but they finally provide the proper bass depth and all the richness of tonal shades.
| + | A small step for humanity, but a significant one for the industry | – | Poor selection of entries |
Verdict – digital sound, which finally raises a few complaints
DSD256 – DSD512 – DSD1024
Quality score – 50%
“Advanced” DSD formats that demonstrate a full physical sensation of sound images. With sumptuous bass and dynamic bursts, DSD feels like the most impressive digital music solution yet.
| + | "Almost" studio sound | – | Small library, some sense of detachment in presentation |
Verdict – audiophile's choice
Vinyl (remake)
Quality score – 60%
Modern records have gotten rid of many of the shortcomings that were noticeable at the turn of the 21st century; now, as a rule, they offer high-quality mastering and absolutely natural sound, colored by the whole gamut of emotions.
| + | If the recording is of high quality, you will get the whole gamut of colors | – | The vinyl system will be more expensive than the digital one |
Verdict – we applaud the analogue renaissance!
Vinyl (first presses)
Quality score – 70%
The original LP versions are still the standard for vinyl records. Other versions cannot match their dynamic range, power and flow.
| + | Luxurious bass, the spirit of the era is before you | – | Difficulty finding records in perfect condition |
Verdict – the first press is worth hunting for
Magnetic tape
Quality rating – 100%
The standard for today. The format of record labels, the “Holy Grail” of music, has recently become available to the masses – high-quality recordings at 38 cm/s have finally reached the homes of the most advanced audiophiles. There are now dozens of companies on the market selling such tapes - and, believe me, once you hear such quality, it will be very painful to lower the bar. The tape immediately shows the poverty of other music reproduction schemes - its dynamics are head and shoulders above anything available on the market, and the emotions of the author's performance seem to penetrate straight into your soul. If you want to find out what you lost earlier, check out the reel-to-reel entry, but remember, there is no turning back. Yes, and you will have to tinker with the choice of bobbin .
Source
The most rare
.RAW - A raw file can contain audio in any format, but is typically used with PCM audio data. It is rarely used except for technical testing.
.SLN is a validated linear PCM format used by Asterisk. Prior to v.10, the standard audio types were 16-bit Signed Linea.
.Vox - most often uses the Dialogic ADPCM (Adaptive Differential Pulse Code Modulation) codec. Like other ADPCM formats, it compresses data to 4 bits. Vox format files are similar to wave files, except that they do not contain information about the file itself, so audio playback formats may differ. To do this, you will first need to specify the codec sampling rate and the number of channels.
A note about data types
When reading the header, you can use different types of data. For example, in C (MSVS), instead of a char[4] array, you can use __int32 or DWORD, but then comparison with some string constant, for example, may not be very convenient. I would also like to warn you about 64-bit operating systems. Namely: it is always worth remembering that in the C language, the variable type int in a 64-bit system will have a length of 8 bytes, and in a 32-bit system - 4 bytes. In such cases, you can use the above-mentioned variable type __int32 or __int64, depending on the size of the variable in memory you need. There are types __int8, __int16, __int32 and __int64, they are available only for the MSVC++ compiler of at least version 7 (Microsoft Visual Studio 2003.NET), but you can’t go wrong with the choice of data type size.
Where can you find hardware audio codecs today?
It depends, you have to take into account that the power of processors today is so great compared to not so long ago that many functions that were previously dependent on dedicated hardware have reverted back to the processor. It is the audio codec that is usually found on audio cards, being a small chip on the board. motherboard or inside some other component. But since this is a part that is no longer paid attention to, the inclusion of hardware audio codecs can be found in high-end hardware.
It's possible that your PC's CPU itself controls the sound of your favorite game or series without you realizing it. After all, audio decoding requires only a fraction of the processor's power. However, this does not mean that it does not affect the overall system performance. But given the trend of keeping audio codecs on many PCs, most applications today tend to ignore them and are designed to be able to use the user's CPU exclusively.
Nowadays, hardware audio codecs are so integrated and miniaturized that we can find them in high-quality speakers and headphones, performing positional audio interpretation functions in combination with motion sensors of the user or the speaker itself according to their orientation.