Basic
An audio signal, in general, is encoded by a sequence of signal amplitude values measured at regular intervals. A single amplitude value is called a sample, and the time between two adjacent measurements is called the sampling frequency or quantization frequency. In the vast majority of cases, a sample when transferred to an audio device is described as a signed integer - 16, 24 or 32 bits. The 32-bit width can be used to align the device buffer on a double-word boundary, in which case the sample is encoded with only the first 24 bits, or for full-bit encoding. The first option is available in ASIO and WASAPI, the second only in WASAPI.
The maximum achievable signal-to-noise ratio is determined by the sample bit depth and is calculated as 20log(2^q) where q is the sample bit depth.
16 bits - sample range [−32768, 32767], SNR 96.33 dB 24 bits - sample range [−8388608, 8388607], SNR 144.49 dB 32 bits - sample range [−2147483648, 2147483647], SNR 192.66 dB
Due to the mutual multiplicity, sampling rates (the number of samples per second for one channel) should be written in two sets: {44100, 88200, 192000} and {48000, 96000}. The two sets of frequencies mean that an audio device needs two oscillators for good synchronization. Of course, you can use one with a multiple of the frequency, for example, both 88200 and 96000 Hz, but this significantly increases the complexity of executing an accurate clock circuit.
Conclusion : a high-quality audio device must have two oscillators, one for working with frequencies {44100, 88200}, the second for {48000, 96000, 192000}.
DSP
When processing a digital signal (DSP - digital sound processing), the sample is scaled to at least a 64-bit floating point number (double64) in the range from –1 to 1. The most commonly used conversions are upsampling/downsampling and upscale/downscale. The second is to change the sample bit depth and in the vast majority of implementations comes down to simply scaling the 64-bit double to the desired bit depth. This transformation, in addition to scaling the useful signal, does exactly the same scaling of the noise, so upscale does not change the signal-to-noise ratio of the original signal, and downscale additionally increases the share of noise due to degradation of the bit depth of the useful signal.
Upsampling/downsampling is very often done through solutions of an nth order polynomial (usually cubic). A sequence of K-samples is taken and the coefficients of the interpolating polynomial are calculated from them, then the resulting polynomial is solved for new sampling points. Ideally, according to the Nyquist-Kotelnikov theorem, upsampling can only preserve the resolution of the original signal at the new sampling rate. In a non-ideal case, noise may appear at higher harmonics. Interestingly, downsampling after upsampling will return the original value of the signal, even if distortion and noise appeared in it after upsampling.
Studios use algorithms that combine upsampling and upscale into a single process to increase signal resolution and dynamic range. These algorithms cannot be used for real-time playback.
Another case of DSP processing is convolution, which is used to adapt the signal to the acoustic properties of the room. Here the original signal is decomposed into harmonics in a Fourier series up to the nth order. Unfortunately, all fast algorithms usually work with the amplitude of a signal of a certain frequency without taking into account the phase (which is still very difficult to measure correctly). Moreover, fast algorithms do not solve the integral, but take the average value in the range. As a result, all correction is reduced to a parametric equalizer. Simple bandpass filters introduce phase distortion at the crossover frequencies, which is why the convolution parameters need to be adjusted again and again.
MQA at high harmonics, in my opinion, incrementally encodes the first derivative (slope) of the signal's amplitude function. Knowing the frequency of the encoding harmonics, it is very easy to extract and restore the behavior of the derivative using a simple Fourier series expansion. And having a derivative, you can already do upsampling not with polynomials, but with splines with smoothing. Then, in real time, you can do upsampling and upscale with increasing resolution and dynamic range of the signal. Of course, this will not be the original Hi-Res, but it will be something.
Conclusions : Upscale does not improve the signal-to-noise ratio. Upsampling does not improve signal resolution. Upsampling makes sense to go from the 44100 to 48000 line if your device's oscillator is better for 48000. Using room correction requires iterative tuning and is largely unpredictable.
Russian Blogs
In a computer system, if you need to output sound, you must use a special method to control the sound chips, such as codec, DAC and so on. In the process of mobilizing the sound chip, some special application programming interfaces, that is, audio APIs, are required. Using the Audio API, audio programs such as players can create output programs directly for the API without using different instructions for different chips.
Common audio APIs are MME, DS, WDM, KS, WASAPI, ASIO, etc.
MME(WaveIn/WaveOut)
MME is the most common Windows Audio API, called MutiMedia Extensions, that is, multimedia extension technology. It has a long history and good compatibility, and basically all devices on the market can be well supported. It is a high-level API and does not interact directly with the hardware; it requires a layered interface to access the audio hardware, which also results in high latency. While this delay does not degrade audio quality during audio playback, it does have a greater negative impact on audio processing and recording.
MME uses the waveIn **** / waveOut **** API to complete audio processing. After running the program, use the waveIn **** series function to open the sound card's input function, at the same time set the buffer to a small enough value, and then start recording audio data to the specified buffer, and then to the buffer when the buffer is full. (WAVHDR) can be directly added to the waveOut **** series function output queue. This method is relatively easy to implement. The downside is that MME is a high-level API, so it needs to go through all the system processing steps in the entire process, which results in a lot of latency. If the buffer is too small, it will cause intermittent sound. Typically, the minimum latency can be up to approximately 120 milliseconds.
WaveOut is the earliest audio stream output method proposed by Microsoft, so its compatibility is good, almost all Microsoft operating systems and sound cards support it, but it cannot support the "mixing multiple audio streams" feature without using hardware acceleration. ,All mixing activities are performed using software.
DirectSound(DS)
After the release of Windows95, Microsoft found that gamers were still willing to use DOS as a gaming platform, as game developers found that Windows95 was not suitable for video and audio tasks because the multimedia features included in WinAPI32 were too slow to respond. Then Microsoft released the famous DirectX, DirectX is a set of audio and video DSP (effect) API audio APIs. DirectSound is part of it. DirectSound is split into 2D/3D. DirectSound has effector features so you can also add echo and other effects during output to simulate a real-life sound environment. DirectSound primarily provides services for games. Some players and audio editors also use DirectSound as a real-time effects API. DirectSound focuses on the output and there is no input. As long as the hardware supports it, DirectSound can significantly speed up response times. Windows audio responsiveness has been improved to new levels. With the exception of some ancient sound cards, almost all sound cards support DirectSound, at least DirectSound 2D.
In November 2006, Microsoft released Windows Vista. Vista suddenly dropped support for the DirectSound 3D hardware level (HAL), meaning those sound cards that support DirectSound 3D hardware acceleration have lost their acceleration capabilities. The recently released Windows 7 inherits this feature from Vista, and DirectSound 3D hardware acceleration comes out of the past.
DirectX Sound focuses on audio output and can directly access hardware, and responsiveness has been greatly improved. Set the DirectSound operating mode to the highest level, typically the minimum latency can be around 60 milliseconds.
WDM
WDM is an acronym for Windows Driver Module, which has low latency and supports multiple audio streams. This is a new feature in Windows 98 SE/ME/2000. Since the introduction of the WDM driver, people have discovered that sound cards that previously did not support multiple audio streams can play multiple audio streams. WDM can also be thought of as a set of APIs. The object of communication is the driver, not the normal application. As long as the driver supports WDM, many features will be added, such as a general purpose soft wave table. In terms of input and output, WDM is better than MultiMedia Extensions and DirectSound. Now almost all sound cards that were not excluded support WDM. WDM can significantly reduce sound card latency. In some cases it can even be comparable to ASIO. Some professional audio editing and production programs support WDM.
MME has high latency and Direct Sound is not designed for professional audio. The advent of WDM makes up for these shortcomings. WDM communicates directly with the audio chip driver, eliminating a large number of intermediate channels and reducing latency to new levels. Nowadays, many professional audio programs provide WDM interfaces.
The so-called WDM technology is where applications directly call underlying system services. The general process is to first receive data from the buffer and then output it. Under WinXP, WDM audio is also known as Kernel Streaming. The advantage of this design is that latency can be extremely low, typically the minimum latency can be anywhere from 1 millisecond to 10 milliseconds, and under certain circumstances non-paged memory, direct hardware IRP and RT can be used to monopolize all sound card resources.
Kernel Streaming(KS)
Stream core in Chinese means stream core, which is a way to directly access the underlying data, it can bypass the system mixer (Windows kernel mixer) and communicate directly with the sound card, which improves output efficiency and reduces output latency. The streaming kernel does not go through Kmixer, but directly processes the audio data in kernel mode so that we can hear the original audio.
However, Kernel Streaming also has its limitations: first, using this API will directly occupy the audio hardware. When you listen to a song, you don't hear QQ audio, secondly, this API doesn't have audio input function and you can't use microphone.
It should be noted that since Vista and Win7 started to move away from kmixer and dma dependent I/O, the threading kernel is not applicable to Vista and Win7.
UAA(WASAPI)
UAA is the latest Windows audio architecture that was introduced at the launch of Vista. UAA is called Universal Audio Architecture, that is, universal audio architecture, and the API for controlling audio conversations is WASAPI (Windows Audio Session API). WASAPI can handle each group of audio conversations individually, which makes a big difference.
For example, when using WASAPI, if you play music with a sample rate of 44.1 kHz, but QQ with a sample rate of 48 kHz audio rings again, you do not need to solve it with reverb, and there will be no sample rate conversion (SRC). Sound quality deteriorates. In fact, the WASAPI audio API is the standard for many music lovers.
WASAPI (Windows Audio Session API) is an API related to the UAA (Universal Audio Architecture) audio architecture that was added after Windows Vista. WASAPI allows unmodified bitstreams to be transmitted to audio equipment, thereby avoiding SRC (sample rate conversion) interference. For Windows XP, a channel similar to WASAPI is the streaming kernel mentioned above. WASAPI can only be used in Vista and Win7 and above.
Microsoft claims that Vista/7 began to move away from kmixer and dma dependent I/O and developed what it called WaveRT (Wave RealTime). Their WASAPI, MMCSS, etc. use WaveRT as the core, and WaveRT has its own mixer, but you can bypass the mixer, as long as you run the exclusive touch mode, mute all other programs. MMCSS allows you to increase the audio I/O priority to the highest clock speeds. What Microsoft wants to do is actually use a real time control timer Audio stream, without dma, communicate directly with UAA audio devices, or even allow the sound card or audio interface software clock to directly control the audio data, this feature should be very similar to ASIO, even if it's WASAPI sharing mode, SRC no longer exists, but in the console you can freely set the general purpose sample rate, bit size and channels after sharing the mix so that you can keep the original 44100 Hz signal and it won't be SRC, and now All Intel motherboard or Intel chips already have HPET (High Precision Event Timer), which you can do ideo and audio processing more accurately handles high sample rate and low bus latency in real time, so the number of times on data stream events can be react per second increases significantly, but I don't know if AMD has it.
ASIO
The full name of ASIO is "Audio Stream Input Output", which is an audio technical specification proposed by the German company Steinberg, and is one of the audio API standards. The main features of ASIO are low latency and multi-channel multi-channel transmission. ASIO completely eliminates the central hardware control of the Windows operating system and can implement multi-channel transmission between audio processing software and hardware, while simultaneously reducing system response time to an audio stream to a minimum.
The native Windows driver for MME has a latency of 200~500ms, DirectSound 50~100ms, and Mac OS Sound Manager 20~50ms. When ASIO is used, the buffer can be up to Below 10 milliseconds and there are also cases where it is less than 1 millisecond due to better environment. Therefore, real-time processing can be achieved in music recording and production operations.
Low latency is important for audio recording and post-production, but the impact on audio playback is controversial. Some enthusiasts believe that ASIO's low latency can significantly reduce audio jitter, thereby improving audio quality, but another saying is that ASIO places strict demands on hardware and software environments. If the sound driver is written at a general level, it is easy to create problems such as crackling and cold sound.
EAX
EAX stands for Environmental Audio Extensions, which is not a set of independent APIs, but a set of 3D APIs built on top of DirectSound 3D, developed by the famous Creative. Creative launched EAX to compete with A3D and eventually win the market. Following the groundbreaking acquisition of Aureal, EAX introduced some of A3D's advanced algorithms.
OpenAL
OpenAL is a free cross-platform audio 3D API developed by Loki Software, but Loki Software failed shortly thereafter: the free software community took over further development, with Creative becoming the de facto leader. Since Vista dropped support for DirectSound 3D hardware acceleration, Creative also found itself in a difficult position: the only way to continue EAX development was to strengthen OpenAL support. Creative hopes to reverse engineer EAX using OpenAL. This step is not difficult to achieve, but it needs widespread support from game manufacturers to be widely used. Today, OpenAL support is still not as good as DirectSound 3D, and it will take time for Creative to replicate its glory. But if you try to succeed, you can get great benefits because OpenAL is the only cross-platform API.
Software player
I will limit myself to considering the Windows architecture as the most accessible and optimal for creating digital transport. Windows provides three options for accessing the audio device: Kernel Streaming, Direct Sound, WASAPI. Plus, the vast majority of audio devices come with an ASIO driver. Of the listed methods, only Direct Sound and ASIO are full-fledged audio interfaces with DSP capabilities: upsampling/downsampling, upscale/downscale, volume control and mixing. In addition, ASIO has the ability to expand the audio path using plugins.
Kernel Streaming and WASAPI are low-level protocols for controlling various devices, including audio. At the same time, the burden of any DSP signal processing falls on the software player using these protocols. Modern high-quality software players use WASAPI and/or ASIO, since both of them provide the ability to asynchronously transfer audio data from computer memory to the memory of an audio device.
Just in case, I’ll note that computer memory and audio device memory are physically different chips. During operation, the software player has access only to the computer’s memory, where it generates audio data. Rewriting of generated data from one memory to another is carried out by the audio device driver.
WASAPI and ASIO have an almost identical operating principle: the player prepares data in the clipboard and indicates the address of this buffer to the protocol, then it prepares the next buffer and waits until the protocol finishes processing the first one. Since the process of data preparation and its reproduction occur in parallel, the protocols are called asynchronous. WASAPI, unlike ASIO, has two operating modes.
The first mode is “sharing” of the device, where several processes can simultaneously transfer data to the device. The second mode is “exclusive”, when the device is locked for exclusive use by only one program (one client). ASIO operates exclusively in exclusive mode. From the point of view of playback, there is no difference between WASAPI and ASIO, except perhaps for the possibility of transmitting a full-bit 32-bit sample via WASAPI (ASIO, even if it supports this mode, will still use only the first 24 bits out of 32).
As noted above, upscale does not improve the signal-to-noise ratio and, since I have never seen a full-bit 32 source file, there is no difference between WASAPI and ASIO. However, as a programmer and as a listener, I prefer WASAPI, naturally in exclusive mode. But this is purely a matter of taste and personal liking.
Conclusion : if you (like me) reproduce an audio signal without DSP processing, then you can use any (*) software player that supports WASAPI Exclusive and/or ASIO.
(*) see the next section carefully.
WASAPI, DS, KS, ASIO
A number is a number, but at some point audio lovers were faced with claims that software players sounded differently. They began to subjectively evaluate playback on foobar2000, jriver, winamp, aimp, aplayer, and myth busters reported that they heard the difference, for some one player worked, for others another.
Considering the proprietary code of many players, we are unable to analyze and find the reasons for this behavior, but in addition to the player, part of the computer’s operating system is also involved in audio playback. Those. This is a component that is responsible for playing sound in the OS.
Different operating systems have different audio capabilities, and even within the same family of operating systems, there may be different methods for interacting with audio.
For example, Linux initially used the OSS sound architecture (Open Sound System from 4Front Technologies),
which was used for professional purposes with musical equipment - it sounded great, but there were conflicts with the license - OSS was then released under a closed license, and the community demanded the GPL. Therefore, having quarreled, some Linux programmers simply decided to write an audio system from scratch and created ALSA.
Alsa was not better (it sounded even worse, at least at the initial stage, I haven’t compared it at the moment), it didn’t even have a normal mixer, I had to add the pulseaudio crutch, but the GPL licenses were complied with.
I still remember the time when, for better sound, I specifically chose the OSS sound architecture in Linux in order to listen to a more “tasty and lively” performance represented by Supermax.
At the moment, Alsa dominates Linux, and a number of popular distributions have cut OSS even from the kernel, so it’s simply not possible to attach OSS to the same Ubuntu without recompiling the kernel, and the more democratic Arch Linux will allow you to use OSS. There is another small problem - if previously all audio programs were written for the OSS sound architecture, and when alsa appeared they did not work (that’s why a compatibility module was written and when installing it, OSS programs think that they work with OSS, although in fact they work with the “new” one) ALSA using aoss from the alsa-oss package), now it’s the other way around - modern Linux programs only work with ALSA and they will have to be deceived with a similar module for OSS - they will think that they are working with ALSA, but in fact with OSS (osspd - OSS Proxy Daemon).
What I really liked about the OSS sound core is that it is a true Unix Way, i.e. absolutely Unix approach - everything is files, and with any device I can do everything the same as with a regular file, copy to it, from it, read, write.
TrueOS - desktop BSD system
Your sound card in Linux is a file called dsp (as well as audio), which is located in the /dev folder.
To play a music file (raw or PCM) I can simply copy the file (or redirect playback) to the DSP device and listen to the music without using any players at all.
For example like this
cat music.wav > /dev/dsp
or so
cp mucic.wav /dev/dsp
Well, you understand this magic of Unix power.
But, to finish you off, I will also say that since the dsp file is a sound card, then I can record something on it. If you write from it, then it is a microphone (or another device if you change the default settings).
Accordingly, I can record sound from a microphone to a file without any third-party programs, like this, for example:
cat /dev/dsp > mysound.wav
This is all OSS could do. Alsa can’t do this - it has a lot of crutches that have to be configured among themselves in many configuration files. But the license is GPL (sarcasm). In fact, Linux OSS is now also GPL, but the train has left.
A little translation from wikipedia :
The OSS project was originally free software, but after the success of the project, Savolainen signed a contract with 4Front Technologies and patented support for new audio devices and improvements. In response, the Linux community abandoned the OSS implementation included in the kernel, and development efforts shifted to a replacement, the Advanced Linux Sound Architecture (ALSA). Some Linux distributions, such as Ubuntu, have chosen to disable OSS support in their kernels and ignore any errors related to OSS4 packages (though OSS support may be re-enabled in Ubuntu).
Despite this, several operating systems, such as FreeBSD, continued to distribute previous versions of OSS and continue to support and improve these versions.
In July 2007, 4Front Technologies released the source code for OSS under CDDL for OpenSolaris and GPL for Linux.
In January 2008, 4Front Technologies released OSS for FreeBSD (and other BSD systems) under the BSD license.
At the same time, both OSS and ALSA are professional and excellent-quality audio architectures that give digital audio direct access to an external device (while maintaining bit perfect, of course).
This ideal option in Windows is called ASIO ( Audio S stream I nput / O utput ). And if in Linux the ALSA architecture and, for the most part, OSS supports everything that you have as an audio card, then in Windows only devices with special drivers from the manufacturer containing ASIO can qualify for this (and this is not all devices).
Therefore, we get the shortest direct sound for nothing in Linux, but in Windows it is not for everyone and not always, but more on that later.
OSS in Linux is not an outdated system, it is a modern system that is still being developed, the latest version is OSS4. It’s just that in Linux, for ideological reasons (not for sound reasons), it is relegated to the background (see above).
But in the family of true Unix BSD operating systems - FreeBSD, OpenBSD, PC-BSD, TrueOS, etc. - OSS is the only sound system.
PC-BSD
Someone asked on a thematic forum why ALSA was not ported to BSD, to which they answered: why, OSS has everything without the crutches, like in ALSA. Of course, ALSA also has a plus - support for new audio chips appears (most likely) most quickly there due to greater support.
Therefore, the easiest way to experience the beauty of OSS4 is to install a BSD-based OS.
I have planned audio experiments with FreeBSD and its OSS 4.2 for the near future, but for now let’s return to WIndows.
Does Windows sound bad?
To begin with, it’s a good idea to understand what kind of Windows we’re talking about. Windows XP, Windows 7, Windows 8, etc. are still in use.
In Windows XP, everything was bad with sound, what can we say, there you used the DirectSound architecture by default - a very indirect way designed to add gaming effects because DSound was part of the DirectX gaming API.
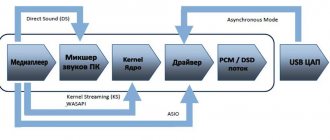
From the picture we can see how long the sound path in Windows XP is along the DirectSound path. The familiar mixer especially cruelly spoiled the sound.
I think you can easily find the measured graphs and verify this, as I did in preparation for writing this review.
Therefore, it was obvious that good sound can only be obtained from ASIO, for which drivers are not available for every audio device.
But the days of XP have passed and the era of Windows Vista/7 has arrived, which I also do not recommend using today.
Her diagram:
Microsoft tried to improve sound quality, which resulted in the WASAPI * (Window Audio Service API) layer.
Many noted the increased quality thanks to WASAPI, but it is worth noting that WASAPI is not a shortcut (the left side of the picture), also pay attention to the block called KST inside WASAPI - this is KS - kernel stream. The foobar2000 program has a separate module for implementing kernel stream - its use will greatly shorten the path of digital sound to the audio device (everything that is “before” will be thrown out), and also, logically, will deprive you of the ability to control, for example, the volume/mixer.
We see that KS is very similar to ASIO, but unfortunately its implementations are quite unstable and it can only be used if it works on your specific computer and is not buggy.
The sound path through KS is the shortest
Also note that DirectSound, which many audio lovers complained about for quality, is no longer available here (in Vista, 7 and higher).
You can expose me by looking at the devices in the player, where such a name will be present, but this name, as I understand it, is left for compatibility and in fact everything works via WASAPI in DSound emulation mode.
By the way, WASAPI itself contains a shorter exclusive mode WASAPI exclusive mod (very low latency up to 10 ms), activation of which leads to the removal of a number of components from the sound path, i.e. in fact, WASAPI exclusive leaves only the Kernel Stream on the way, i.e. is content with less blood (let me remind you that the separate KS module is unstable).
ASIO is still the shortest, but we see that both Kernel Stream and WASAPI exclusive allow us to get the highest quality without ASIO.
The audio part has been greatly improved in Windows 10, so I would recommend this OS to audiophiles (or Linux). Windows 10 (1809) at the end of 2022 and the beginning of 2022 finally produced sound on my system that is not inferior to Linux ALSA!
I also note that if you adjust the sound volume through the Windows mixer while listening, you worsen the sound. The volume control in the player and Windows should always be kept at maximum, and the volume should be adjusted on the amplifier itself.
So, let's summarize what interface in the player is better to choose.
If there is no question with Linux and BSD, there is ALSA and OSS, then in Windows we have variations.
In Windows XP there is only one high-quality solution - this is ASIO, provided that such drivers are available for your device.
As for newer OSes, of course it’s worth switching to Windows 10 and keeping in mind that there is no DirectSound anymore - there is only emulation of this mode via WASAPI (more details).
The remaining choice is between ASIO, which is not available for all devices, between KS (kernel stream, which may be unstable) and WASAPI.
Regardless of stability, these variations are distributed (hypothetically) like this (higher is better):
1. ASIO
2.KS
3.WASAPI
Path via WASAPI
ASIO is great for today's popular XMOS, Amanero, etc. transports, but if you use other devices, ASIO drivers may simply not exist.
Advanced audio enthusiasts will argue that there is a universal asio4all driver, but what profit are you going to get from it if it actually works through WASAPI?
Those. There is no point in ASIO4ALL on Windows above XP for listening to audio.
In the conditional second place is Kernel Stream (KS), it transmits directly, like ASIO data, directly to the recipient, in this case a DAC, but KS is buggy with a number of equipment, and it’s not a fact that it will work for you, and in addition, more However, I know of a sane KS plugin only for the Foobar2000 player. Overall, KS is good, it has a path shorter than WASAPI, but again it may not work for you.
That leaves WASAPI. For audiophile tasks, we are only interested in the WASAPI exclusive mode, which actually cuts off most of the unnecessary stuff, leaving only KC and a little more. We get wildly low latency (delays) down to 10 milliseconds, just like in ASIO! Well, actually, I have one Korg ASIO interface, it has 1ms latency, but this is not typical, even for ASIO devices.
And in fact, there are no hidden reasons not to use the native one, which supports everything and everyone WASAPI exclusive without any glitches, getting, in fact, the same thing as in other cases.
Those. hypothetically I would use ASIO first. If it doesn't work, then KS. If it doesn't work, then WASAPI exclusive. But in terms of sound, they all give great sound and there is no reason to get hung up on one option - it will sound the same. Just choose what is more convenient for you to use. And, yes, there is no more terrible, non-audiophile DSound.